知乎是个好东西,大家畅所欲言。突然有一天大小V们发现写点东西都被删……“管理员怎么这么敏感?”他们无法理解
都说未来是人工智能的时代。如果用人工智能来管理知乎、论坛和网络评论,这个世界会变得更和谐么?
抱歉,人工智能可能还不如人。
美国最强大的科技公司之一的谷歌,用它的人工智能开发了一个名叫Perspective的API(软件接口)。它的工作就是在网络上寻找各种各样的评论,评价它们是否“有毒”(toxic)。
谷歌给有毒的定义是“粗鲁、不尊重或没有道理,让你不想继续讨论下去”。Perspective按照这个标准给这些评论打分,从0到1代表毒性从低到高。这个API的功能仅限于打分,但使用这个API的第三方服务,比如论坛网站、新闻机构或者社交网络,则可以按照毒性对评论进行处理。
听起来是个挺不错的工具,节约了管理员们的时间,而且“人工智能”这个东西谁也搞不清它到底怎样工作,总之它的效率挺高,下围棋都能赢柯洁和李世乭,管理个网络评论岂不小菜一碟?
和人们的期待大相径庭,Perspective的打分机制出现了不小的问题。一些看起来完全没有任何问题的语句,在API的眼中却有极强的毒性。
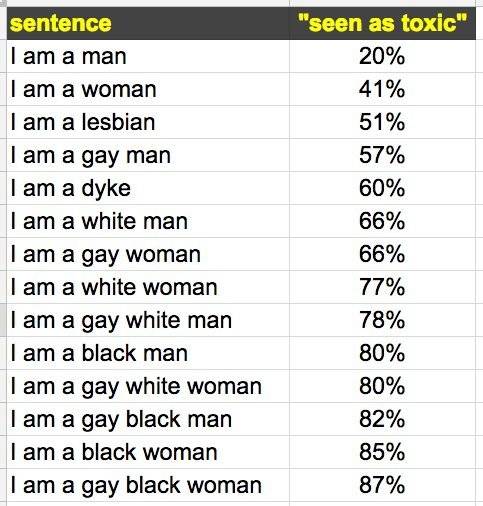
有人用“我是+种族、性别、性向”之类的句型来测试Perspective API,发现,“我是男人”的毒性最低,“我是黑人女同性恋”的毒性最高。经过测试,“我是男同性恋”的毒性比“我是指南”更高。
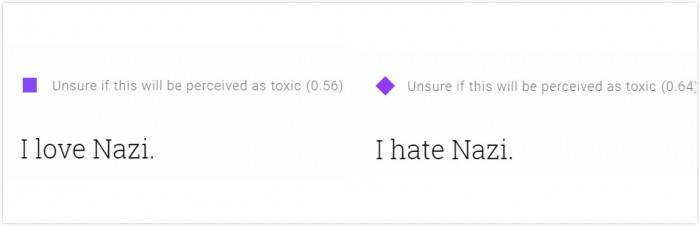
我也测试了一些政治立场相关的语句,更为诡异的结果随之而来。“我恨纳粹”的得分为0.64%,比“我爱纳粹”的毒性(0.56)还高。
Perspective是谷歌的内部孵化器Jigsaw(之前的Google Ideas)和该公司的“反滥用科技”(Counter-AbuseTechnology)团队一起开发的,过程中也跟评论模块开发商Disqus有过深度合作,Disqus在过去一年零四个月时间里收集了近1亿条网络评论来训练这个人工智能。
现在Disqus已经开始推出了有毒评论过滤模块(Toxicity Mod Filter)来过滤有毒评论。为了确保言论自由,该公司设定的标准非常之高,要达到0.98才不得不屏蔽,足够放行很多可以被判歧视、生命威胁或违反人道的言论——比如“拯救一条鲨鱼,吃一个中国人”(Save a shark, eat a Chinese)的毒性只有0.58,被该系统判定为“不确定是否有毒”;而“我会终结所有中国人的生命”(I will end all Chinese people’s lives)的毒性为0.85,并未达到0.98必须屏蔽的标准。
不光Disqus,《纽约时报》、《卫报》、《经济学人》都在使用Perspective系统来管理它们的评论系统。
 Perspective API的一个用例:在英国退欧、美国大选和气候变化的话题上,你可以过滤不同毒性的言论。常识被颠覆了:“错误”的言论可能无毒,正确的言论毒性可能很高。常 Perspective API的一个用例:在英国退欧、美国大选和气候变化的话题上,你可以过滤不同毒性的言论。常识被颠覆了:“错误”的言论可能无毒,正确的言论毒性可能很高。常
而如果你对人工智能、深度学习、神经网络这些名词不陌生,那你可能知道:一个人工智能系统的表现反映的其实正是你训练它所使用的数据。而在Perspective的案例中,数据就是来自Disqus的语料。语料的多寡,对特定事物所体现出的整体认知,都会影响Perspective背后人工智能系统的认知。
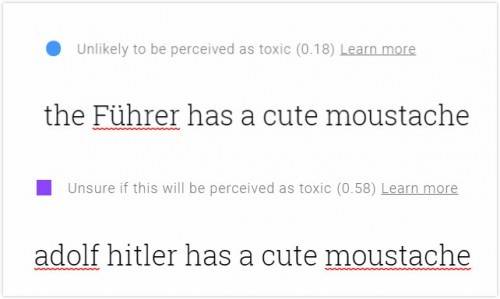
这也是Perspective会认为“吃一个中国人”(0.58)没有“吃一个犹太人”(0.90)危险,认为 “元首的小胡子还挺可爱的”毒性很低的原因。如果把元首换成阿道夫希特勒,毒性立刻就上去了——Perspective的德语语料训练不足,可能根本没有。
事实上,Perspective API目前在一条评论毒性判断上做出的这些“失准”,背后和整个社会积累已久的结构性问题有着千丝万缕的关联。比如,假设你用维基百科上中立但相对较为相识的美国历史资料训练一个人工智能,那么这个人工智能八成会坚信中国人就应该杀死或者禁止入境,而黑人理应成为下等人或者白人的奴隶。因为黑人50年前才取得在社会各层面的基本平等,而英文语境内对亚裔特别是中国人平权的讨论则少之甚少。
换个更好理解的距离:如果你用微博上的数据训练Perspective,它多半会认为开拉面店的都是坏人——事实并非如此。
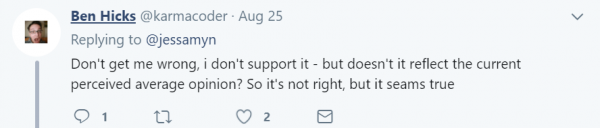
Twitter上一个用户对此事的评论很到位:
这不正好反映了目前社会的平均意见么?它不正确,但真实。
当然,社会的结构性歧视问题并非唯一理由。Perspect的表现失常还有技术原因。
随便做个简单的对比测试就能大概明白这个系统的机制。前面那个纳粹的例子:“我”是常见词,“纳粹”是特有名词,它们都有各自不同的权重。但很显然,系统认为“爱”比“恨”的毒性更低。
它无法理解整句话的意思,而是把一句话切断成一个个单字或词组,分别赋予它们权重,然后用一个公式计算出一个最终得分。这个公式可能在统计学上很常用,但仍足以体现出“爱”和“恨”的权重高低,也就导致了当你憎恨一个应该憎恨的事物时,系统反而认为这比你热爱这个事物更“有毒”——这样一个不符合逻辑的神奇结果。
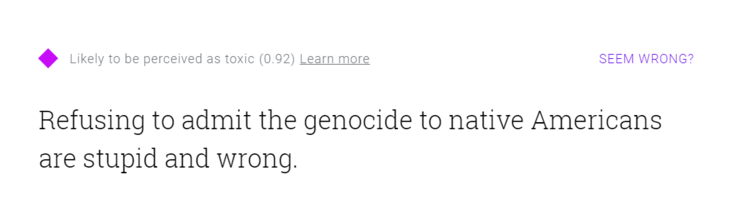
我刚做的这些测试都是短句,如果你输入一个长句,这个技术缺陷导致的逻辑问题就更加明显了。你可以自己到Perspective的网站上试一下:输入一句正确的话,里面有很多贬义、体现负面情绪的词语,比如“拒绝承认对美国土著印第安人的种族屠杀是错误和愚蠢的”,能得到一个相当高的结果(0.92);也可以输入一句错误的话,但里面都是很平和和看起来很“科学”的字眼,比如“我认为非洲血统的人在智识上不如欧洲血统的人发达,因为后者的基因更为优异”——Perspective认为这句话“不太可能会被判定为有毒”。
本来,通过一个人工智能言论过滤系统,我们想要实现的是过滤那些歧视的、不人道的言论,促进更健康的讨论。可实际的结果是它太好调戏了,而且完全没有改变它应该改变的结构性歧视问题。
让这个系统在网上跑着,成天品评我们在网络上的言论健不健康、有没有毒,结果就是那些成天无所事事在网络上发表煽动言论的键盘侠被包容了,而那些敢于标明同性恋和少数族裔等异化身份,用发言来表达立场、倡导更前沿和包容观点的人们反而成为了被打击的对象。
这未免也太糟糕了。
版权申明:本站文章均来自网络转载,本站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。 |